-
[Statistics] 머신러닝 분류기 성능 측정을 위한 지표 accuracy, precision, recall, f1-score 표로 쉽게 계산하기Statistics 2020. 2. 25. 01:28

목차
- 분류기 성능 측정 방법의 종류: 4가지
- TP, TN, FP, FN?
- dataset에서 TP, TN, FP, FN 구해보기
- accuracy, presicion, recall, f1-score 구해보기
- 마치며
분류기 성능 측정 방법의 종류: 4가지
분류기(classifier)의 성능에 대한
4가지측정 방법이 있다.- accuracy
- precision
- recall
- f1-score
이들을 계산하려면, 한 가지 개념이 더 필요하다. 바로
TP, TN, FP, FN!TP, TN, FP, FN?
개념은 간단하다.
- TP (True Positive)
- TN (True Negative)
- FP (False Positive)
- FN (False Negative)
처음 봤을 땐 매우 매우 헷갈리는데, 난 하나의 포맷을 만들어서 이해했다.
일단
TP, TN, FP, FN는 모두 두 개의 문자를 가졌으니자리를 분리해서 이해해보자!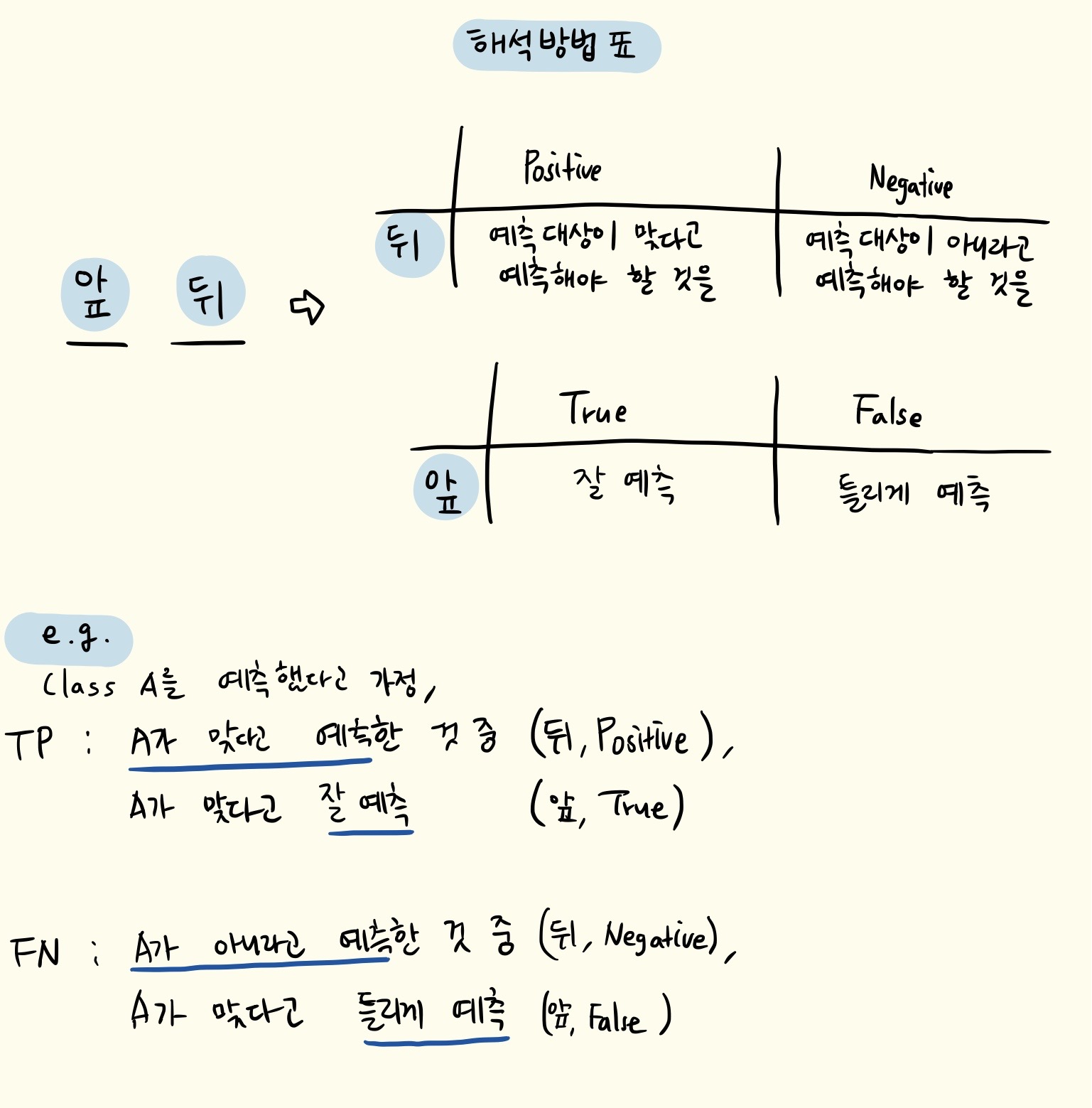
약간의 말장난 같기도 한데..
머신러닝 모델이 예측을 맞춘 경우에 1을 1이라고 해서 맞췄는지, 1이 아닌 걸 1이 아니다 라고 해서 맞췄는지는 분명 다르기 때문에 개념을 분리해서 사용하나보다..!
dataset에서 TP, TN, FP, FN 구해보기
-
위의 손글씨 노트에서 가정했던 것처럼,
class A를 예측한다고 가정 -
표 (멀티클래스 분류기)
-
행(가로줄)은 모델에 넣어 준 input을 의미 -
열(세로줄)은 모델이 예측한 output을 의미 -
+) 바이너리 분류기는 2개의 클래스가 있다고 생각하고 표 그리기
-
1. TP (True Positive)
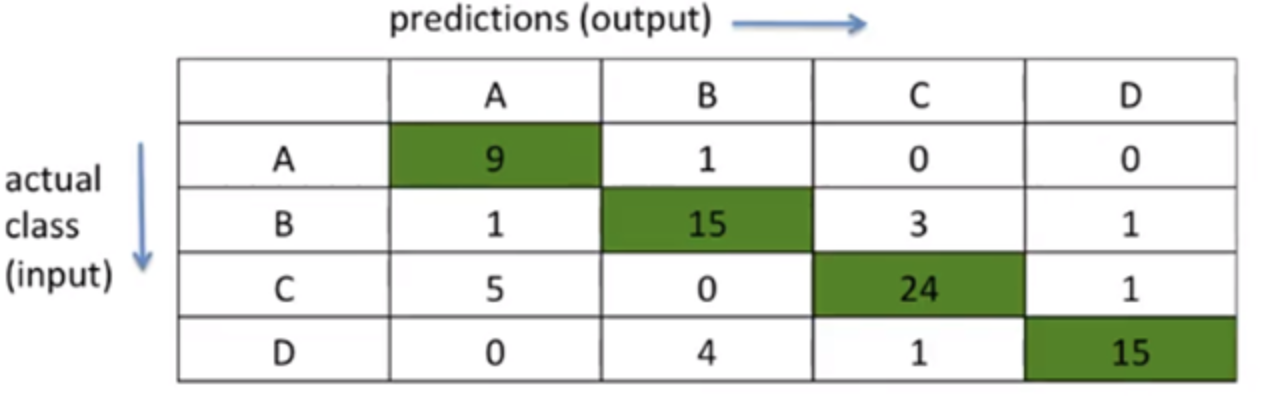
TP: output이
A라고 예측한 것 중(P), input을A라고 잘 예측한 것(T)class A에 대해서는, 표에서 왼쪽 위
9가 써져 있는 초록칸만해당2. TN (True Negative)
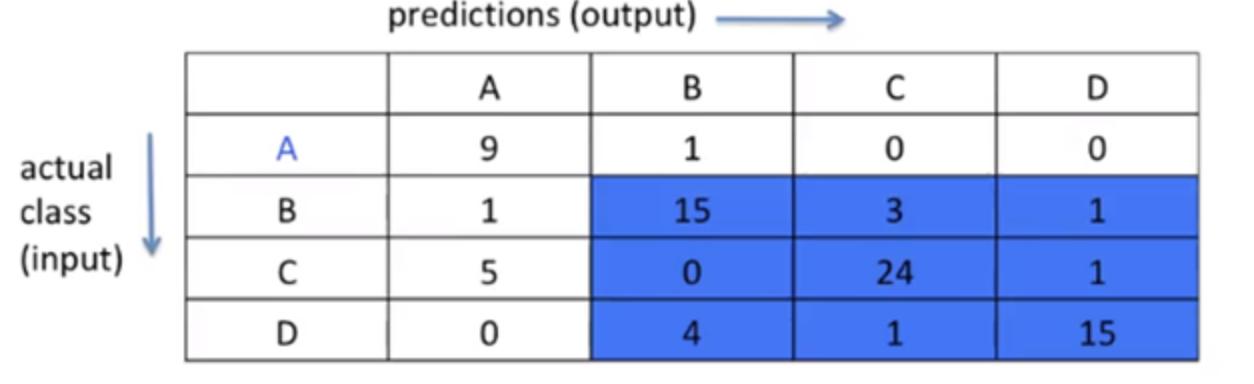
TN: output이
A가 아니라고 예측한 것 중(N), input을A가 아니라고 잘 예측한 것(T)다른 예시하나만 더 들어보면, 이번엔 A말고D를 예측한다고 해보자!그럼 이렇게 나오겠지?
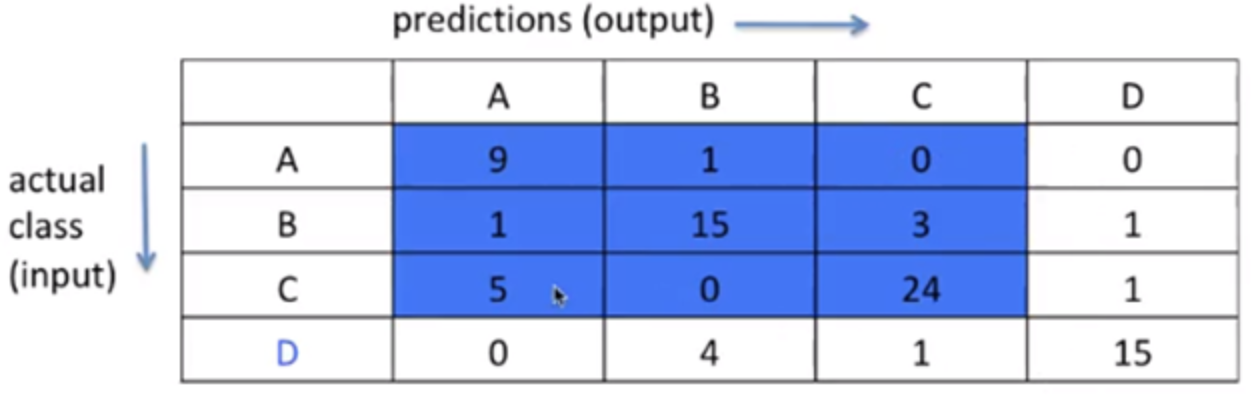
TN: output이
D가 아니라고 예측한 것 중(N), input을D가 아니라고 잘 예측한 것(T)3. FP (False Positive)
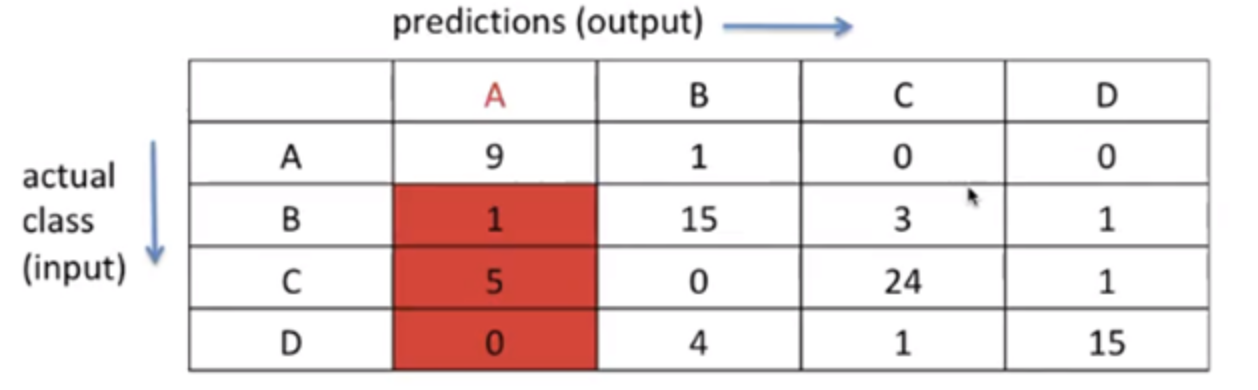
FP: output이
A라고 예측한 것 중(P), input을A가 아니라고 틀리게 예측한 것(F)다른 예시하나만 더 들어보면, 이번엔 A말고B를 예측한다고 해보자!그럼 이렇게 나오겠지?
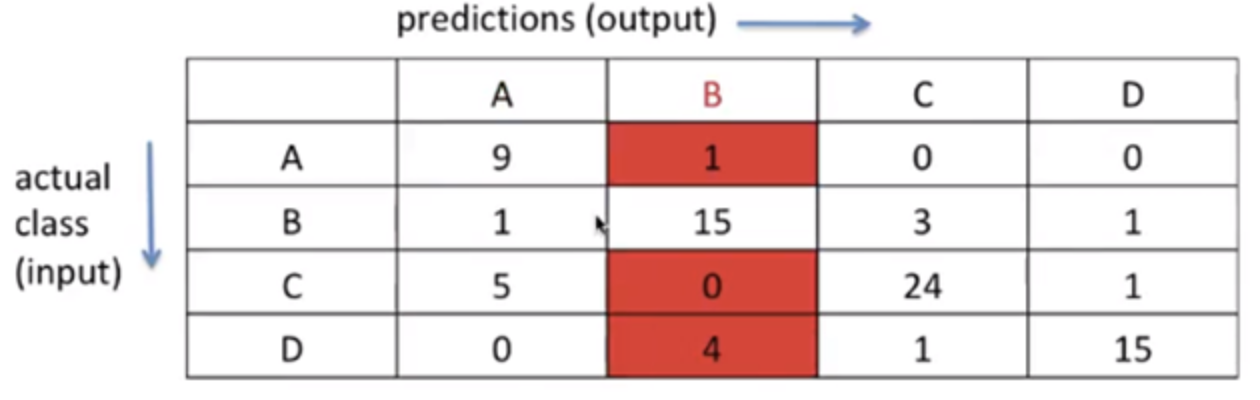
FP: output이
B라고 예측한 것 중(P), input을B가 아니라고 틀리게 예측한 것(F)4. FN (False Negative)
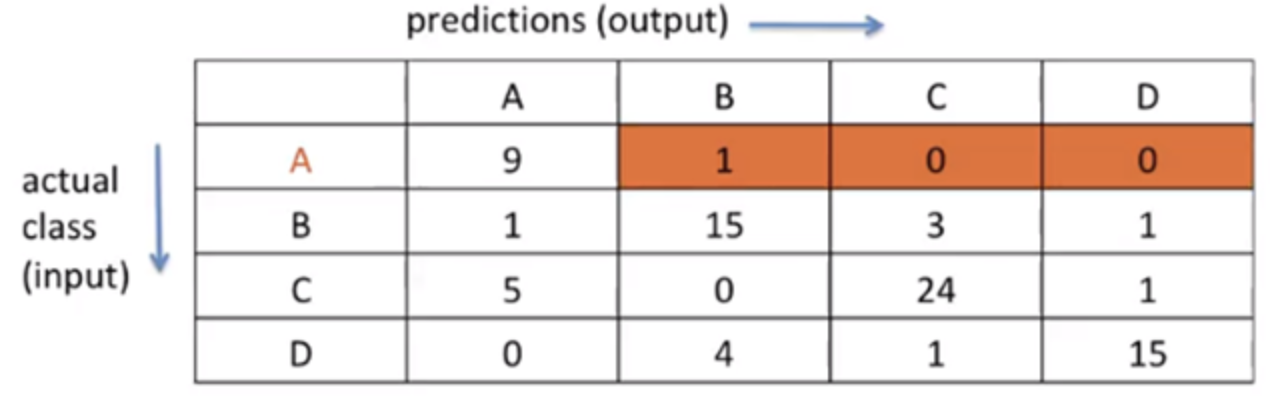
FN: output이
A가 아니라고 예측한 것 중(N), input을A라고 틀리게 예측한 것(F)accuracy, presicion, recall, f1-score 구해보기
이제 본격적으로 구해보자!
1. accuracy
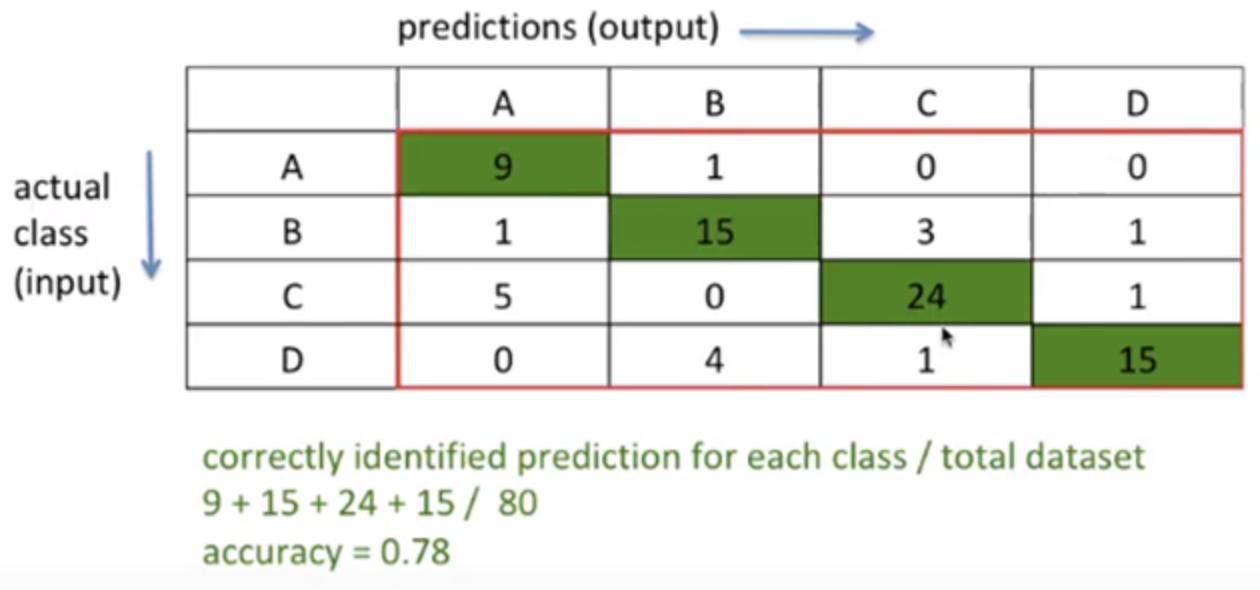
accuracy = TP+TN / TP+TN+FP+FN이진 분류기의 accuracy는 TP+TN / TP+TN+FP+FN로 구하지만,
다중 분류기의 accuracy를 구할 때는, 클래스 따지고 어쩌고 어렵게 생각하지 말고 그냥
표의대각선의 합 / 전체 셀의 합을 구하자!2. precision
precision과 recall은 좀 헷갈릴 수 있는데, 먼저 계산하는 법부터 설명하고 아래에 차이점을 설명하겠다.
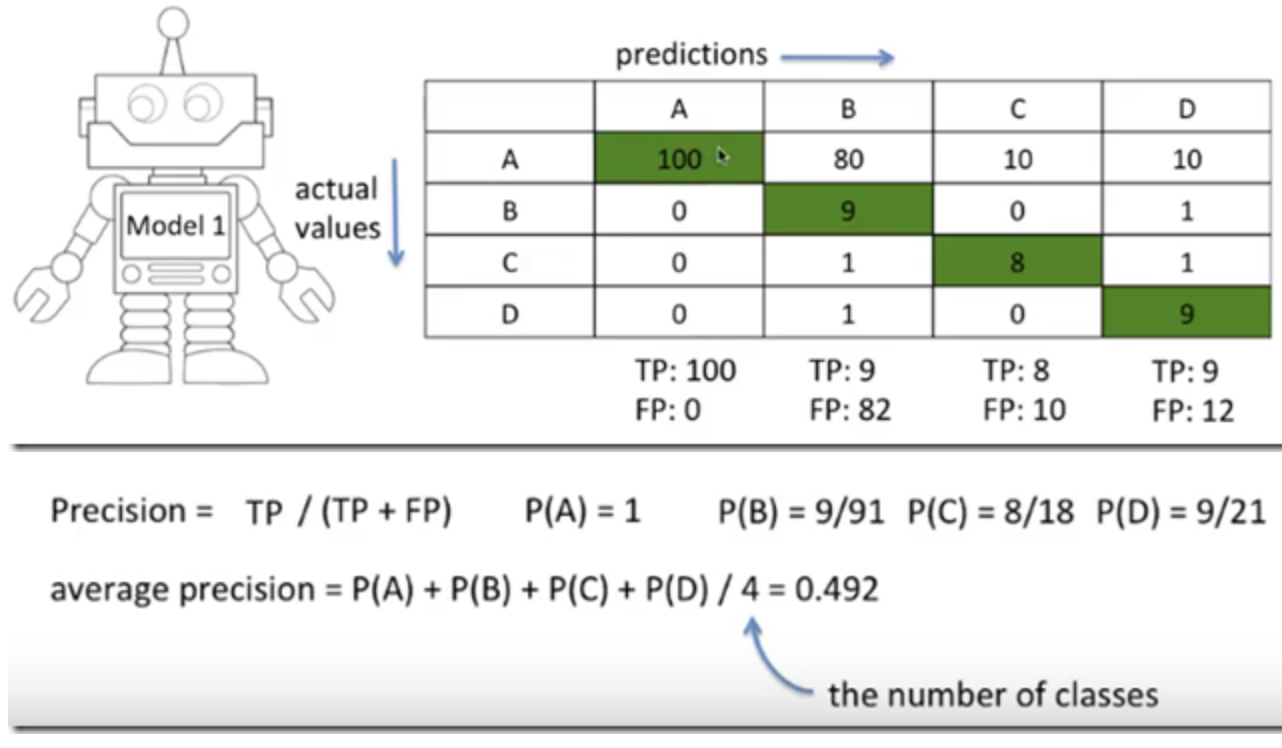
precision = TP / TP+FPclass A에 대해,
precision = TP / TP+FP =분모 중에 잘 예측한 것 / output이 A인 모든 것
(그림에선 전체 클래스 다 구하고 있다)3. recall
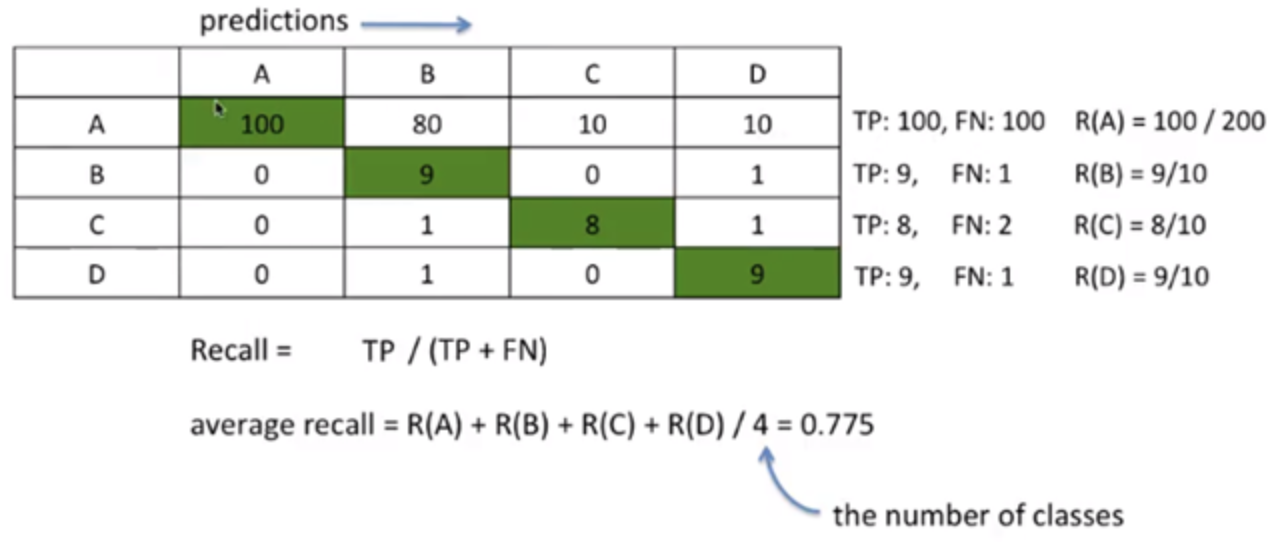
recall = TP / TP+TNclass A에 대해,
recall = TP / TP+TN =분모 중에 잘 예측한 것 / input이 A인 모든 것
(그림에선 전체 클래스 다 구하고 있다)+)precision과 recall의 차이점
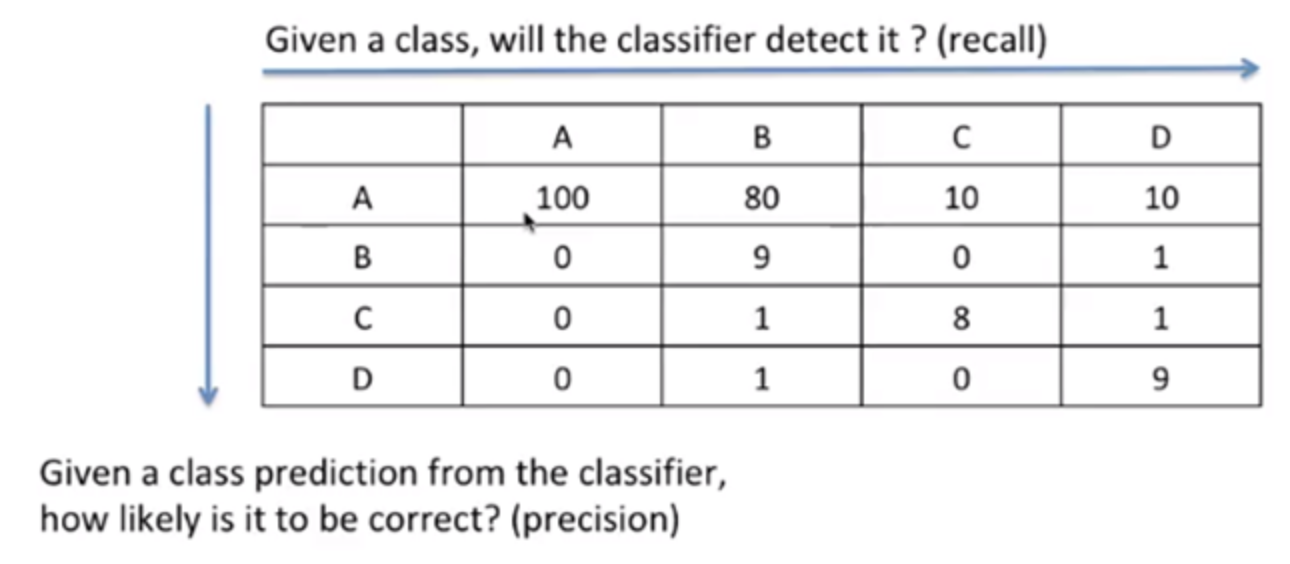
precision = TP / TP+FP = 분모 중에 잘 예측한 것 / output이 A인 모든 것 recall = TP / TP+TN = 분모 중에 잘 예측한 것 / input이 A인 모든 것잘 보면,
precision은 output에 대한 정확도를 나타내고
recall input 대한 정확도를 나타내고 있다.
즉,precision은 모델이예측한 것에 대해 얼마나 맞췄는지계산을 한거고recall은 모델이dataset에 대해 얼마나 맞췄는지계산한 거다.4. f1-score
만약, dataset의 클래스 분포가
imbalanced하다면, accuracy를 보는 것이 의미 없을 수 있다.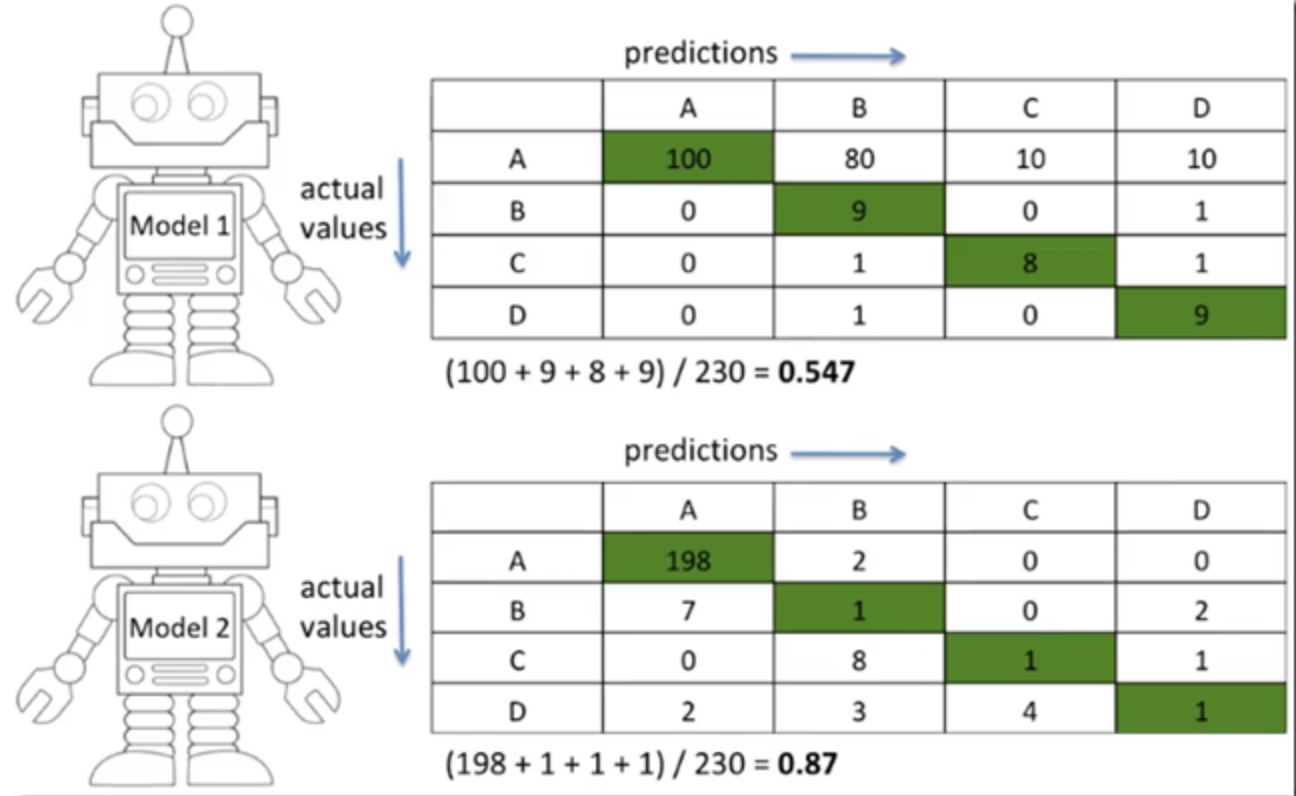
위의 그림과 같은 경우
accuracy는 아래 분류기가 더 높지만,
class A를 많이 맞춰서 높아진거지 나머지 B, C, D는 많이 못맞춘 것을 볼 수 있다.이럴 때 f1-score를 이용한다.
f1-score는 앞서 언급한 precision과 recall의 조화평균이다.
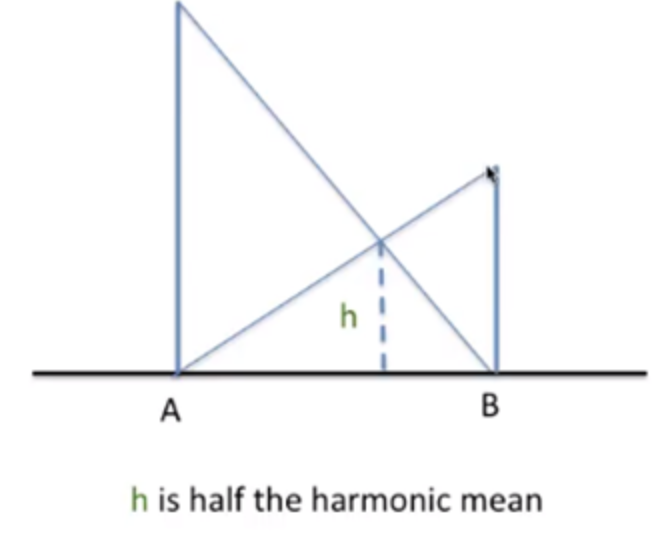
h = 2 * AB / (A+B)A와 B의 조화평균은 이렇게 구한다.
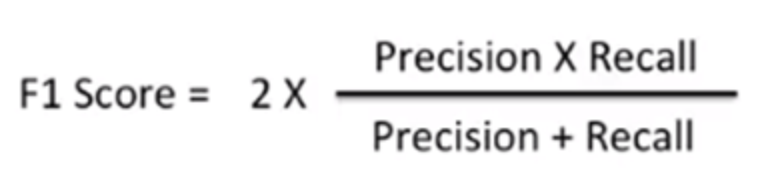
이처럼
A와 B에 precision과 recall을 넣었을 때의h가 바로 f1-score이다.따라서, dataset이
imbalanced하다면accuracy보다 f1-score를 보는 것이 좋다.마치며
여기까지 인공지능 분류기 모델의 성능을 측정할 수 있는 4가지 지표를 알아봤다.
이건 헷갈릴 수 있는 개념이므로 꼭 완전히 이해하고 넘어가자!
reference> https://www.youtube.com/watch?v=8DbC39cvvis&feature=youtu.be