-
[NLP] 신경망의 활성화 함수들 (Activation Functions of Neural Network)ML/NLP 2020. 3. 13. 00:19

퍼셉트론의 장단점
퍼셉트론은 장단점이 있다.
-
퍼셉트론? 관련 게시물> https://dokylee.tistory.com/23?category=379193
장점은 퍼셉트론으로 복잡한 함수도 표현할 수 있다는 것
단점은 가중치를 설정하는 작업은 여전히 사람이 수동으로 한다는 것
신경망은 퍼셉트론의 단점을 해결해준다.
가중치 매개변수의 적절한 값을 데이터로부터 자동으로 학습하는 능력이 신경망의 중요한 성질이다.
퍼셉트론에서 신경망으로

신경망의 예 (2층 신경망) 이렇게 생긴 것이 신경망이다. 퍼셉트론이랑 별 차이 없어 보이는데 맞다 차이가 없다고 한다. 근데 개념이 하나 더 추가되긴 한다. 살펴보자.
퍼셉트론 복습을 잠깐 하자면,

[figure 1] 퍼셉트론을 수식으로 나타내면 위와 같다고 했다. (이전 포스팅에서)
[figure 1]을 더 간결한 형태로 작성해보자. 이를 위해서 조건 분기의 동작(0을 넘으면 1을 출력하고 그렇지 않으면 0을 출력)을 하나의 함수 h(x)라 하자.
그러면 수식은 다음과 같이 바뀐다.

[figure 2] [figure 2]의 첫 번째 식은 입력 신호의 총합이 h(x)라는 함수를 거쳐 변환되고, 그 값이 y의 출력이 됨을 나타낸다. 두 번째 식인 함수 h(x)는 입력이 0을 넘으면 1을 돌려주고, 그렇지 않으면 0을 돌려줌을 나타낸다.
결과적으로 [figure 1]과 [figure 2]이 하는 일은 같다.
활성화 함수의 등장
위에서 등장한 h(x)는 뭐라고 부를까!
이처럼 입력 신호의 총합을 출력 신호로 변환하는 함수를 일반적으로 활성화 함수라 한다.
즉, 활성화 함수는 입력 신호의 총합이 활성화를 일으키는지를 정하는 역할을 한다.
수식을 다시 보자.

가중치가 달린 입력 신호와 편향의 총합을 계산하고, 이를 a라고 한다. 그리고 그 a를 함수 h()에 넣어 y를 출력하는 흐름이다.
이는 아래 그림처럼 나타낼 수 있다.

활성화 함수
1. 계단 함수 (step function)
[figure 2]의 h(x)와 같은 활성화 함수는 임계값을 경계로 출력이 바뀌는데, 이런 함수를 계단 함수라 한다.
그래서 퍼셉트론에서는 활성화 함수로 계단 함수를 이용한다고 할 수 있다.
그렇다면 활성화 함수를 다른 걸로 바꾼다면?
그것이 바로 신경망으로 나아가는 핵심 키이다.
2. 시그모이드 함수 (sigmoid function)
시그모이드 함수의 수식은 다음과 같다.
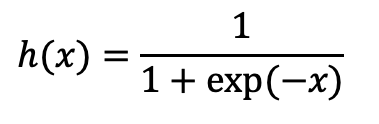
계단 함수랑 시그모이드 함수를 구현해보자
1. 계단 함수 (step function)
import numpy as np import matplotlib.pylab as plt def step_function(x): return np.array(x>0, dtype=np.int)x = np.arange(-5.0, 5.0, 0.1) y = step_function(x) print(type(y)) plt.plot(x, y) plt.ylim(-0.1, 1.1) plt.show()
Out:

2. 시그모이드 함수 (sigmoid function)
# np.exp(-x)가 넘파이 배열을 반환하기 때문에 return값도 넘파이 배열의 각 원소에 연산을 수행한 결과를 내어줌 def sigmoid(x): return 1/(1+np.exp(-x))x = np.array([-1.0, 1.0, 2.0]) sigmoid(x)
Out: array([0.26894142, 0.73105858, 0.88079708])
x = np.arange(-5.0, 5.0, 0.1) y = sigmoid(x) plt.plot(x, y) plt.ylim(-0.1, 1.1) plt.show()
Out:

계단 함수랑 시그모이드 함수를 비교해보자
두 개를 겹쳐서 봐보자.
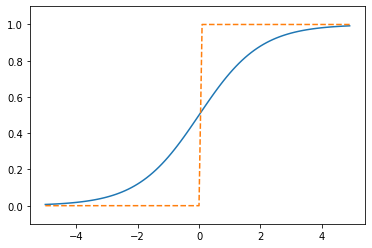
차이점
---
'매끄러움'의 차이가 보일 것이다.
계단 함수는 0을 경계로 출력이 갑자기 바뀌는 반면, 시그모이드 함수는 부드러운 곡선이며 입력에 따라 출력이 연속적으로 변화한다.
계단 함수가 0과 1 중 하나의 값만 돌려주는 반면, 시그모이드 함수는 실수(0.731.... 0.880 ... 등)를 돌려준다는 점도 다르다.
다시 말해 퍼셉트론에서는 뉴런 사이에 0 혹은 1이 흘렀다면, 신경망에서는 연속적인 실수가 흐르게 된다.
공통점
---
계단 함수와 시그모이드 함수는 입력이 중요하면 큰 값을 출력하고 입력이 중요하지 않으면 작은 값을 출력한다.
입력이 아무리 작거나 커도 출력은 0에서 1 사이라는 것도 공통적이다.
또한 둘 모두 비선형 함수다.
비선형 함수
신경망에서는 활성화 함수로 비선형 함수를 사용해야 한다. 달리 말하면 선형 함수를 사용해서는 안된다.
이유는 -> 선형 함수를 이용하면 신경망의 층을 깊게 하는 의미가 없어지기 때문이다.
선형 함수의 문제는 층을 아무리 깊게 해도 '은닉층이 없는 네트워크'로도 똑같은 기능을 할 수 있다는 데 있다.
예를 들어, 선형 함수인 h(x) = cx를 활성화 함수로 사용한 3층 네트워크가 있다고 하자.
이를 식으로 나타내면 y(x) = h(h(h(x)))가 된다.
이 계산은 y(x) = c * c * c * x처럼 곱셈을 세 번 수행하지만, 실은 y(x) = ax와 똑같은 식이다. (a = c^3)이 예처럼 선형 함수를 이용해서는 여러 층으로 구성하는 이점을 살릴 수 없다. 그래서 층을 쌓는 혜택을 얻고 싶다면 활성화 함수로는 반드시 비선형 함수를 사용해야 한다.
또 다른 활성화 함수, ReLU
신경망 분야에서 최근에 ReLU(Rectified Linear Unit, 렐루)라는 활성화 함수를 많이 사용한다고 한다.
ReLU는 입력이 0을 넘으면 그 입력을 그대로 출력하고, 0 이하이면 0을 출력하는 함수이다.
수식은 다음과 같다.

python 구현도 해보자!
def relu(x): return np.maximum(0, x)x = np.arange(-5.0, 5.0, 0.1) y = relu(x) plt.plot(x, y) plt.ylim(-1, 6) plt.show()
Out:

이렇게 활성화 함수 세 가지를 알아봤다!
reference:

- 밑바닥부터 시작하는 딥러닝 1
- 국내도서
- 저자 : 사이토 고키 / 이복연(개앞맵시)역
- 출판 : 한빛미디어 2017.01.03
'ML > NLP' 카테고리의 다른 글
[NLP] 신경망 학습을 시작해보자 : 손실 함수를 중심으로↗ (0) 2020.03.18 [NLP] 신경망의 활성화 함수들 (Activation Functions of Neural Network) - 3 (0) 2020.03.14 [NLP] 신경망의 활성화 함수들 (Activation Functions of Neural Network) - 2 (0) 2020.03.13 [NLP] 딥러닝의 기원이 되는 알고리즘 : 퍼셉트론 Perceptron (0) 2020.03.03 [NLP] Numpy와 Matplotlib 라이브러리 jupyter로 스터디↗ (0) 2020.02.28 -