-
[NLP] 합성곱 신경망 CNN : 합성곱 연산, 배치 처리, 풀링 계층ML/NLP 2020. 5. 10. 01:32

이번 포스팅의 주제는 합성곱 신경망(Convolutional Neural Network, CNN)이다.
CNN은 이미지 인식과 음성 인식 등 다양한 곳에서 사용된다. 특히, 이미지 인식 분야에서 딥러닝을 활용한 기법은 거의 다 CNN을 기초로 한다.
CNN의 메커니즘을 설명해보고, 다음 포스팅에서 파이썬으로 구현해보겠다.
전체 구조
기존의 신경망에서는 못봤던 게 새로 등장한다.
합성곱 계층(convolutional layer)과 풀링 계층(pooling layer)이다.
합성곱 계층과 풀링 계층을 자세히 설명하기 전에, 이 계층들을 어떻게 조합하여 CNN을 만드는지 보겠다.
지금까지 본 신경망은 인접하는 계층의 모든 뉴런과 결합되어 있었다.
이를 완전연결(fully-connected, 전결합)이라고 하며, 완전히 연결된 계층을 Affine 계층이라는 이름으로 구현했었다.
이 Affine 계층을 사용하면, 예를 들어 층이 5개인 완전연결 신경망은 [그림 1]과 같이 구현할 수 있다.

그림 1 [그림 1]과 같이 완전연결 신경망은 Affine 계층 뒤에 활성화 함수를 갖는 ReLU 계층(or Sigmoid 계층)이 이어진다.
이 그림에서는 Affine-ReLU 조합이 4개가 쌓였고, 마지막 5번째 층은 Affine 계층에 이어 Softmax 계층에서 최종 확률 결과를 출력한다.

그림 2 [그림 2]와 같이 CNN에서는 '합성곱 계층 Conv'과 '풀링 계층 Pooling'이 추가된다.
CNN의 계층은 'Conv-ReLU-(Pooling)' 흐름으로 연결된다. 풀링 계층은 생략되기도 한다.
[그림 2]의 CNN에서 주목할 또 다른 점은 출력에 가까운 층에서는 지금까지의 'Affine-ReLU' 구성을 그대로 사용할 수 있다는 점이다.
또한, 마지막 출력 계층에서는 'Affine-Softmax' 조합을 그대로 사용한다. CNN에서 흔히 볼 수 있는 구성이다.
합성곱 계층
CNN에서는 패딩(padding), 스트라이드(stride) 등 CNN 고유의 용어가 등장한다.
또한, 각 계층 사이에서는 3차원 데이터같이 입체적인 데이터가 흐른다는 점에서 완전연결 신경망과 다르다.
먼저 CNN에서 사용하는 합성곱 계층의 구조를 자세히 살펴보자.
완전연결 계층의 문제점
완전연결 계층의 문제점은 바로 데이터의 형상이 무시된다는 사실이다.
입력 데이터가 이미지인 경우, 이미지는 통상 세로·가로·채널(색상)로 구성된 3차원 데이터이다.
그러나 완전연결 계층에 입력할 때는 3차원 데이터를 평평한 1차원 데이터로 평탄화해줘야 한다.
그래서 완전연결 계층은 형상을 무시하고 모든 입력 데이터를 동등한 뉴런으로 취급하여 형상에 담긴 정보를 살릴 수 없다.
그러나, 합성곱 계층은 형상을 유지한다.
이미지도 3차원 데이터로 입력받으며, 다른 계층에도 3차원 데이터로 전달한다.
그래서 CNN가 이미지처럼 형상을 가진 데이터를 제대로 이해할 가능성이 큰 것이다.
* 특징 맵 feature map :
CNN에서는 합성곱 계층의 입출력 데이터를 특징 맵(feature map)이라고도 한다.
합성곱 계층의 입력 데이터를 입력 특징 맵(input feature map), 출력 데이터를 출력 특징 맵(output feature map)이라고 하는 식이다.
합성곱 연산
합성곱 연산은 이미지 처리에서 말하는 필터 연산에 해당한다.

그림 3 [그림 3]과 같이 합성곱 연산은 입력 데이터에 필터를 적용한다.
위에서 입력 데이터는 세로·가로 방향의 형상을 가졌고, 필터 역시 세로·가로 방향의 차원을 갖는다.
데이터와 필터의 형상을 (높이 height, 너비 width)로 표기하며, 위의 예에서 입력은 (4, 4), 필터는 (3, 3), 출력은 (2, 2)가 된다.
문헌에 따라 필터를 커널이라 칭하기도 한다.
[그림 3]의 합성곱 연산 예에서 이뤄지는 계산을 [그림 4]로 설명하겠다.

그림 4 합성곱 연산은 필터의 윈도우(window)를 일정 간격으로 이동해가며 입력 데이터에 적용한다.
여기서 말하는 윈도우는 [그림 4]의 회색 3x3 부분을 가리킨다.
위의 예에서 보듯 입력과 필터에서 대응하는 원소끼리 곱한 후 그 총합을 구한다.
이 계산을 단일 곱셈-누산(fused multiply-add, FMA)라 한다.
그 결과를 출력의 해당 장소에 저장한다.
이 과정을 모든 장소에서 수행하면 합성곱 연산의 출력이 완성된다.
CNN에서는 필터의 매개변수가 그동안의 '가중치'에 해당한다. 또 CNN에도 편향이 존재한다.
[그림 3]의 과정에 편향까지 포함하면 [그림 5]와 같은 흐름이 된다.

그림 5 [그림 5]와 같이 편향은 필터를 적용한 후의 데이터에 더해진다.
편향은 항상 하나(1x1)만 존재하고, 모든 원소에 더해진다.
패딩
합성곱 연산을 수행하기 전에 입력 데이터 주변을 특정 값(ex. 0)으로 채우기도 한다.
이를 패딩(padding)이라 하며, 합성곱 연산에서 자주 이용한다.
[그림 6]은 (4, 4) 크기의 입력 데이터에 폭이 1인 패딩을 적용하는 모습이다.

그림 6 [그림 6]과 같이 처음에 크기가 (4, 4)인 입력 데이터에 패딩이 추가되어 (6, 6)이 되었다.
패딩은 1 뿐만 아니라 2나 3 등 원하는 정수로 설정할 수 있다.
패딩은 주로 출력 크기를 조정할 목적으로 사용한다.
예를 들어 (4, 4) 입력 데이터에 (3, 3) 필터를 적용하면 출력은 (2, 2)가 되어, 입력보다 2만큼 줄어든다.
이는 합성곱 연산을 몇 번이나 되풀이하는 심층 신경망에서는
어느 시점에서 출력 크기가 1이 되어, 더 이상 합성곱 연산을 적용할 수 없으므로 문제가 될 수 있다.
앞의 예에서는 패딩의 폭을 1로 설정하니 (4, 4) 입력에 대한 출력이 같은 크기인 (4, 4)로 유지되었다.
입력 데이터의 공간적 크기를 고정한 채로 다음 계층에 전달할 수 있어진 것이다.
스트라이드
필터를 적용하는 위치의 간격을 스트라이드(stride)라고 한다.

그림 7 [그림 7]에서는 크기가 (7, 7)인 입력 데이터에 스트라이드를 2로 설정한 필터를 적용했다.
이때 출력은 (3, 3)이 되었다.
이처럼 스트라이드를 키우면 출력이 작아진다. (패딩은 크게 할 수록 출력 크기가 커졌다)
이러한 관계를 수식화 해보겠다.
- 입력 크기 (H, W) / 필터 크기 (FH, FW) / 출력 크기 (OH, OW) / 패딩 P / 스트라이드 S

그림 8 [그림 8]에 값을 대입하면 출력 크기를 구할 수 있다.
단, OH와 OW의 결과값이 정수로 나눠떨어지는 값이어야 한다는 점에 주의하자.
3차원 데이터의 합성곱 연산
[그림 9]는 3차원 데이터의 합성곱 연산 예이다. 그리고 [그림 10]은 계산 순서이다.

그림 9 2차원일 때와 비교하면, 길이 방향 (채널 방향)으로 특징 맵이 늘어났다.

그림 10 채널 쪽으로 특징 맵이 여러 개 있다면 입력 데이터와 필터의 합성곱 연산을 채널마다 수행하고, 그 결과를 더해서 하나의 출력을 얻는다.
3차원의 합성곱 연산에서 주의할 점은 입력 데이터의 채널 수와 필터의 채널 수가 같아야 한다는 것이다.
또 모든 채널의 필터가 같은 크기여야 한다.
블록으로 생각하기
3차원의 합성곱 연산은 데이터와 필터를 직육면체 블록이라고 생각하면 쉽다.
블록은 [그림 11]과 같은 3차원 직육면체이다.

그림 11 3차원 데이터를 다차원 배열로 나타낼 때는 (채널 channel, 높이 height, 너비 width) 순서로 쓰겠다.
[그림 11]에서 출력 데이터는 한 장의 특징 맵이다. 이는 다른 말로 채널이 1개인 특징 맵이라 할 수 있다.
그렇다면 합성곱 연산의 출력으로 다수의 채널을 내보내려면?
필터(가중치)를 다수 사용하면 된다. [그림 12]처럼 말이다.

그림 12 위와 같이 필터를 FN개 적용하면 출력 맵도 FN개가 생성된다.
즉, 형상이 (FN, OH, OW)인 블록이 완성되고, 이 완성된 블록을 다음 계층으로 넘기겠다는 것이 CNN의 처리 흐름이다.
이처럼 합성곱 연산에서는 필터의 수도 고려해야 한다.
그러므로 필터의 가중치 데이터는 4차원 데이터이며 (출력 채널 수, 입력 채널 수, 높이, 너비) 순으로 쓴다.
합성곱 연산에도 편향이 쓰인다. [그림 13]은 [그림 12]에 편향을 더한 모습이다.

그림 13 [그림 13]에서 보듯 편향은 채널 하나에 값 하나씩으로 구성된다.
배치 처리
합성곱 연산도 배치 처리를 지원하고자 한다.
각 계층을 흐르는 데이터의 차원을 하나 늘려 4차원 데이터로 저장한다.
구체적으로는 데이터를 (데이터 수, 채널 수, 높이, 너비) 순으로 저장한다.
데이터가 N개일 때 [그림 13]을 배치 처리한다면 데이터 형태가 [그림 14]처럼 된다.

그림 14 [그림 14]를 보면 각 데이터의 선두에 배치용 차원을 추가했다.
이처럼 데이터는 4차원 형상을 가진 채 각 계층을 타고 흐른다.
주의할 점은 신경망에 4차원 데이터가 하나 흐를 때마다 데이터 N개에 대한 합성곱 연산이 이뤄진다는 것이다.
풀링 계층
풀링은 세로·가로 방향의 공간을 줄이는 연산이다.
예를 들어 [그림 15]와 같이 2x2 영역을 원소 하나로 집약하여 공간 크기를 줄인다.

그림 15 [그림 15]는 2x2 최대 풀링(max pooling)을 스트라이드 2로 처리하는 과정이다.
최대 풀링은 최댓값을 구하는 연산으로, '2x2 최대 풀링'은 그림과 같이 2x2 크기의 영역에서 가장 큰 원소 하나를 꺼낸다.
또, 스트라이드는 2이므로 2x2 윈도우가 원소 2칸 간격으로 이동한다.
참고로, 풀링의 윈도우 크기와 스트라이드 크기는 같은 값으로 설정하는 것이 보통이다.
* 최대 풀링 이외에도 평균 풀링(average pooling) 등이 있다.
풀링 계층의 특징
1. 학습해야 할 매개변수가 없다.
풀링 계층은 합성곱 계층과 달리 학습해야 할 매개변수가 없다. 풀링은 대상 영역에서 최댓값이나 평균을 취하는 명확한 처리이므로 특별히 학습할 것이 없다.2. 채널 수가 변하지 않는다.

그림 16
풀링 연산은 입력 데이터의 채널 수 그대로 출력 데이터로 내보낸다. [그림 16]처럼 채널마다 독립적으로 계산하기 때문이다.3. 입력의 변화에 영향을 적게 받는다 (강건하다)
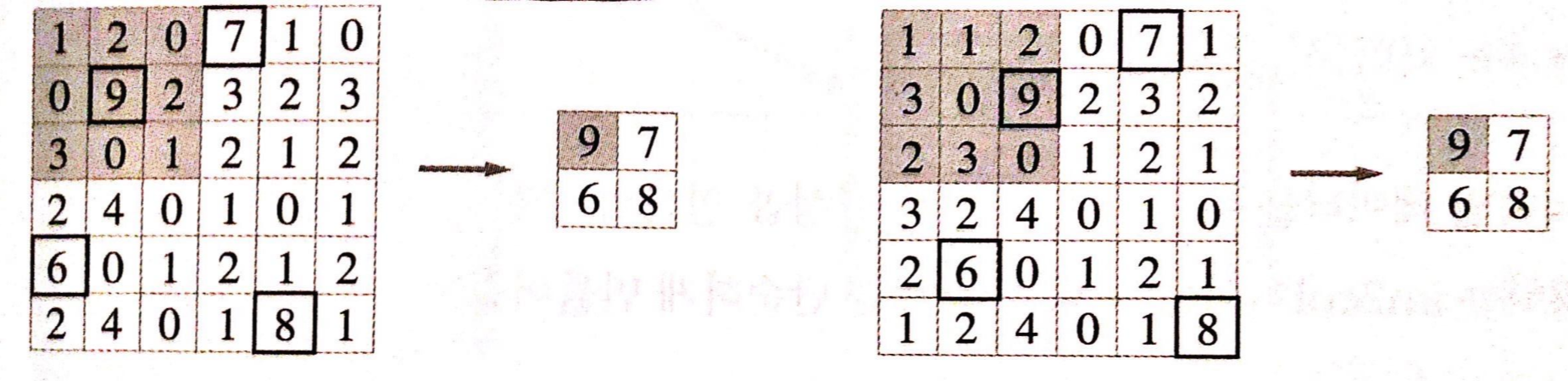
그림 17
입력 데이터가 조금 변해도 풀링의 결과는 잘 변하지 않는다. [그림 17]은 입력 데이터의 차이(데이터가 오른쪽으로 1칸씩 이동)를 풀링이 흡수해 사라지게 하는 모습을 보여준다.'ML > NLP' 카테고리의 다른 글
[NLP] 모두를 위한 딥러닝 : "머신러닝의 개념과 용어" (0) 2020.05.26 [NLP] 합성곱 신경망 CNN : 합성곱/풀링 계층 구현 (1) 2020.05.12 [NLP] 딥러닝 신경망에서 하이퍼파라미터 최적화 구현하기 (0) 2020.04.24 [NLP] 오버피팅을 막아보자: 가중치 감소, 드롭아웃 (0) 2020.04.24 [NLP] 활성화값 분포를 고르게 하는 배치 정규화 Batch Normalization (0) 2020.04.24